Primus: GetYourGuide's Answer to Unified Marketing Analytics
Discover how GetYourGuide revolutionized marketing analytics with 'Primus', a powerful internal data solution. Eugene Klyuchnikov, Engineering Manager, delves into the creation and impact of Primus, addressing a crucial marketing challenge and unifying Product, Marketing, and Supply data for enhanced decision-making.

Staff Data Engineer

Key takeaways:
In this article, Eugene Klyuchnikov, Staff Data Engineer in Marketing and Marketplace Intelligence, shares how Primus - our internal data solution - has changed the way we approach marketing analytics.
{{divider}}
It was a typical meeting in GetYourGuide's Marketing department. The vibe was relaxed, yet the discussions were intense, rife with industry terminology that could easily boggle one's mind.
And then, right in the midst of it all, someone raised their hand and posed a reasonably straightforward question: "How should we go about calculating the Bounce Rate for each Marketing Channel?"
There was a moment of silence, and I must confess, I felt a bit flustered. How could we not have a response to what appeared to be such a fundamental query?
We had some impressive tools at our disposal — a sophisticated attribution system that could trace the flow of revenue and a session performance analyzer with remarkable precision in dissecting user behavior. However, there was a glaring gap in our data toolkit.
None of these tools could seamlessly integrate all the scattered data points into a coherent whole. And so, with a blend of curiosity in true GetYourGuide fashion - and a touch of embarrassment, a new idea took shape. It was our way of reassuring our fellow marketers with a simple message: "Don't worry; we've got this covered!"
Hence, the concept was born to create a product that would unify three crucial aspects of the company — Product, Marketing, and Supply — into a single versatile data solution we aptly named "Primus."
Nevertheless, we quickly realized that the initial step wasn't to develop a new product but instead to collect and organize the data itself. This phase turned out to be both thrilling and challenging, and that's where our story truly begins.
It all started with definitions
Before we even considered writing code or sketching out architectural plans, we became fully immersed in definitions. It became evident that even the most well-established definitions, such as "session" or "search," held hidden complexities that warranted in-depth exploration.
As a result, we decided to confront this challenge head-on. We generated dedicated documents for each definition, providing lucid and formal explanations while engaging in brainstorming sessions to explore diverse ways of giving these concepts substance. It was somewhat reminiscent of the quest to define the perfect cup of coffee — everyone had their unique perspective, and our discussions often ignited lively debates.
But, as the saying goes, "Many hands make light work." We sought input from every corner of the company, spanning from Marketing to Product to Supply. This was a genuine collaborative endeavor, and our determination stemmed from the realization that aligning everyone's understanding was pivotal to crafting a great product.
With our definitions firmly established, it was time to dive in, roll up our sleeves, and make Primus a reality.
Two layers: a delicate balance
When we started collecting details for our data model, we soon found out there was a lot more to it than we thought. The list just kept growing, covering all kinds of data we could think of. It started simple with a few things Marketing needed, but once we got to what the Product team wanted, the list blew up, going over forty different things. That's when we knew we were at an important point where things were going to change.

At this pivotal moment, we faced a choice: build a detailed data model that could do a lot but might run slowly, or go for a simpler model that's quicker but less detailed. So on one hand, we could construct a granular data model that would encompass a wide range of use cases but would likely come at the expense of speed. On the other hand, we had the option of adopting an aggregated model, intentionally reducing the number of dimensions to prioritize usability, even if it meant sacrificing some level of detail.
From past lessons, we knew slow models weren't popular. No matter how valuable they might be, no one wanted to wait for five minutes for each query. It seemed like the second option was the only practical choice.
However, we made a daring decision to take a risk and declared, "This time, we can create a detailed model that's also lightning-fast." It was a bold statement, and our success hinged on it.
The Data Layer
In the early phases of our data journey, we laid the foundation by constructing a comprehensive data model consisting of multiple tables and intricate relationships. Within this model, we meticulously defined critical user actions like sessions, searches, and product page views, enabling us to capture the essence of user interactions on our platform.
During this stage, our primary focus wasn't on optimizing for speed. While the model incorporated date partitioning to facilitate efficient data retrieval, it didn't prioritize lightning-fast query performance. Consequently, executing queries within this layer could sometimes consume several minutes. Nevertheless, this layer played a crucial role in providing our dedicated analysts and product managers with the rich, detailed data necessary to uncover valuable insights and steer the evolution of our platform.
Moreover, we are actively exploring AI capabilities for generating SQL queries, a development that could further enhance the accessibility and popularity of our data retrieval layer.

The Reporting Layer
Expanding upon our data model, we introduced an additional layer focused on session-level aggregation. This innovation enabled us to reduce the volume of data significantly and drastically cut down typical query processing times to just a matter of seconds.
However, aggregation wasn't our only optimization strategy. We implemented several additional measures to enhance performance, including:
1. Strict filtering
We applied rigorous filtration methods to ensure that only sessions worth analyzing were included in the reports. This involved the exclusion of traffic generated by bots and web crawlers, the removal of internal and technical sessions, and the identification and elimination of sessions that exhibited significant deviations from typical patterns (such as sessions originating from atypical locations or displaying dissimilar characteristics to regular sessions).
2. Fighting for every byte
We conducted a thorough analysis of all data fields, carefully eliminating or minimizing any extraneous information. One notable optimization effort focused on reducing the length of automatically generated UUIDs, which were initially 128 characters long, to a more compact 20-character format. Our calculations confirmed that this shortened format still maintained a sufficient level of uniqueness, ensuring that the chances of unintentionally mixing up two distinct sessions were less than one in a million over an extended period. This particular optimization alone enabled us to reduce our data volume significantly by an impressive 40%.
Here's our UDF (user-defined function) for shortening original UUIDs.
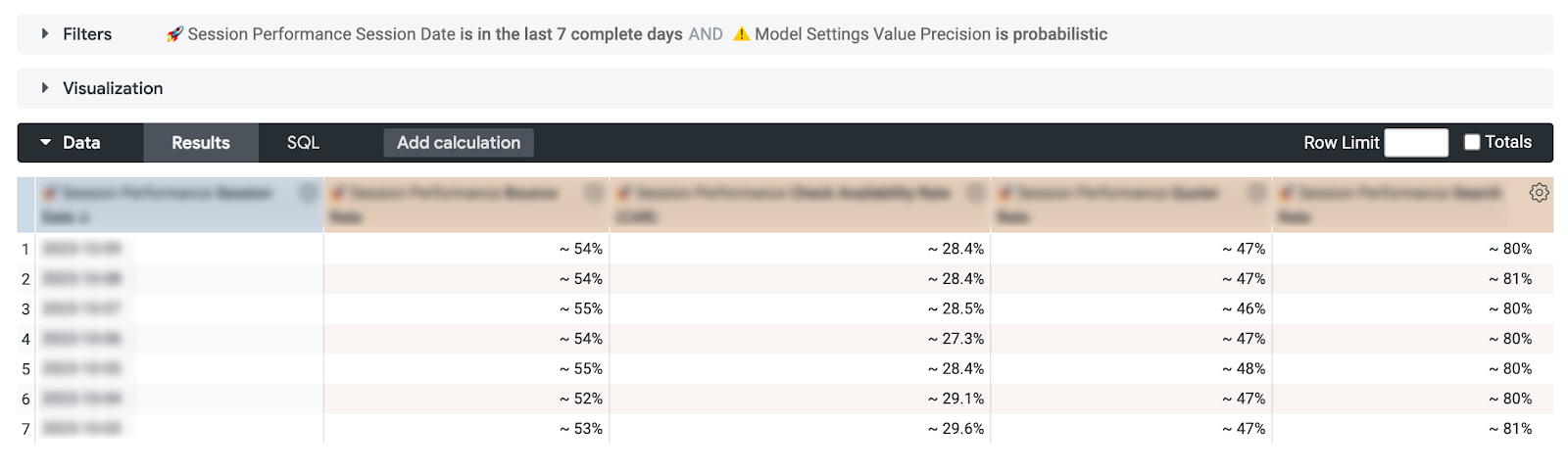
3. Dual retrieval modes for count-distinct metrics
In our data model, most metrics are count-distinct, and we've implemented a solution to improve data retrieval efficiency. For these metrics, we provide users with two retrieval modes: "precise" and "probabilistic." In the latter mode, we harness the capabilities of the HyperLogLog algorithm, which not only accelerates data retrieval significantly but also maintains a relatively low margin of error, standing at just 1.6% compared to the true value.
This approach allows us to strike a balance between query speed and accuracy. Furthermore, we empower our users to make the choice between prioritizing query speed or obtaining precise and accurate results.
4. Responsible usage
With our typically democratic policy to data access at GetYourGuide, Primus became our first data model that required users to read the documentation and pass a concise six-question quiz before gaining access. This was a strategic move, especially because our Looker reporting layer relies on shared resources. We recognized the importance of ensuring users fully grasped the model's limitations. For example, we aimed to prevent instances where users might try to retrieve aggregated data spanning multiple years in a single query, which could strain our resources.
Although this approach demanded extra efforts in promoting Primus, it provided us with the assurance that the model would be utilized responsibly and with an informed understanding of its capabilities and constraints.
Promotion & expansion: fostering Primus growth
Ensuring Primus's visibility and fostering its high-quality usage have been central to our strategy. We've employed several techniques and initiatives to achieve these goals:
- First-class support: We established a dedicated Slack channel, committing to respond to any Primus-related inquiries within a maximum of a couple of hours, though typically within minutes. Additionally, we introduced a special feedback form where users can leave their comments, suggest ideas, or report bugs. This approach encourages users to embrace Primus, knowing their questions won't go unanswered.
- Promotion through "Influencers": We collaborate closely with analysts across all business domains, ensuring they have a profound understanding of Primus's capabilities. They, in turn, collaborate with product managers who then engage with their teams, spreading the word and promoting the adoption of Primus. Furthermore, we regularly host webinars to introduce new users and teams to the platform.
- Aggressive deprecation: We have taken an assertive stance in deprecating and phasing out older models that Primus can now replace. Of course, we provide migration support for reports and data when necessary. This approach not only promotes Primus but also ensures we stay at the forefront of data modeling efficiency.

In retrospect, the decision to embark on this ambitious journey was undoubtedly a risky one. Yet, it has evolved into a remarkable project that has not only met but exceeded our expectations. The satisfaction derived from Primus's success has been immeasurable. We've not only streamlined data retrieval but analysis but also cultivated a thriving community of users who continue to explore, innovate, and drive our data-driven endeavors forward.
In the world of data, risks can lead to remarkable rewards, and Primus stands as a testament to the power of bold ideas and dedicated teams.
Shoutout
It would be impossible for us to deliver Primus without the support, collaboration and feedback of our team members. Special thanks to Pei Xu, Tatiana Kosheleva, and Yonatan Aharon for contributing to the product; Prateek Keshari for reviewing the drafts of this article; Product Analysts for working with us on requirements; and numerous members of the Product, Marketing, and Supply teams for testing the initial solution and giving us tons of feedback.

More articles like this






